GraphRAG 整体框架
三段式生成流水线
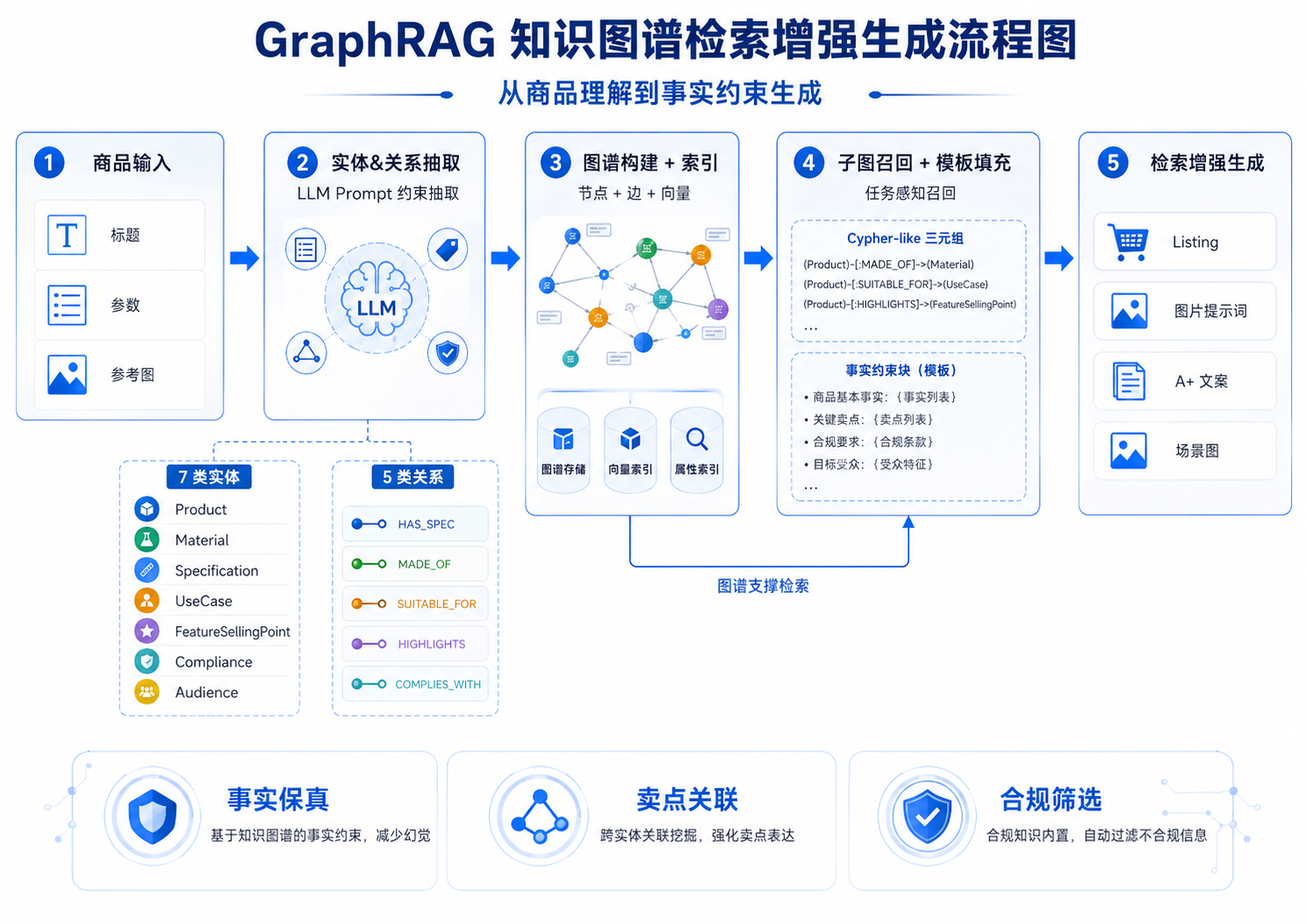
整个流水线由 4 个核心阶段 组成,最终在 Listing / 图片生成阶段注入「事实约束块」,实现从商品理解到事实约束生成的端到端保障。
阶段 1:实体 & 关系抽取
输入
yaml
title: Stainless Steel Kitchen Rack Foldable
parameters: |
- Material: 304 SUS Stainless Steel
- Size: 60×30×80cm
- Folded: 60×30×8cm
- Load: 8kg per tier
references:
- kitchen_real_photo_1.jpg
- kitchen_real_photo_2.jpg处理
通过约束式提示词驱动 Gemini 3 Pro 抽取 7 类商品实体:
| 实体类型 | 示例 |
|---|---|
| Product | Stainless Steel Kitchen Rack |
| Material | 304 Stainless Steel |
| Specification | Size 60×30×80cm, Load 8kg |
| UseCase | Small Kitchen, Bathroom, Outdoor Camping |
| FeatureSellingPoint | Anti-rust, Foldable, Multi-tier |
| Compliance | Lead-Free, Food Contact Safe |
| Audience | Single Apartment Renter, Family |
并构建 5 类语义关系:
| 关系 | 起点 | 终点 | 用途 |
|---|---|---|---|
| HAS_SPEC | Product | Specification | 事实校验 |
| MADE_OF | Product | Material | 视觉渲染 |
| SUITABLE_FOR | Product | UseCase | Lifestyle 提示词 |
| HIGHLIGHTS | Product | FeatureSellingPoint | Bullet 排序 |
| COMPLIES_WITH | Product | Compliance | 违禁词集合差 |
阶段 2:图谱构建 + 索引
持久化
sql
INSERT INTO kg_entities(id, product_id, type, name, attributes, embedding)
VALUES
('ent_001', 'prod_xxx', 'Product', 'Stainless Steel Kitchen Rack', '{...}', BLOB),
('ent_002', 'prod_xxx', 'Material', '304 Stainless Steel', '{...}', BLOB),
...
INSERT INTO kg_relations(id, source_id, target_id, rel_type, weight, evidence)
VALUES
('rel_001', 'ent_001', 'ent_002', 'MADE_OF', 1.0, 'Material: 304 SUS'),
...向量索引
每个实体的 name + attributes 拼接后通过 Gemini Embedding 生成 1024 维浮点向量,存入 BLOB 字段。
后续可做:
- 跨 SKU 相似实体合并
- 模糊查询("不锈钢" 召回 304 / 316 / 哑光不锈钢)
- 实体去重
🔗 详细:存储设计
阶段 3:检索增强生成
任务感知子图召回
不同的生成任务召回不同的子图:
text
任务 → 召回的关系子集
─────────────────────────────────────────────────────
主图生成 → MADE_OF + HAS_SPEC(材质 + 主要规格)
A+ 信息图 → HIGHLIGHTS + HAS_SPEC(卖点 + 规格)
Lifestyle → SUITABLE_FOR + Audience(场景 + 受众)
Bullet 文案 → HAS_SPEC + HIGHLIGHTS + COMPLIES_WITH(全量约束)
违禁词检查 → COMPLIES_WITH(仅合规)模板填充
子图序列化为 Cypher-like 三元组:
text
<MADE_OF, Stainless Steel Kitchen Rack, 304 Stainless Steel>
<HAS_SPEC, Stainless Steel Kitchen Rack, Size 60x30x80cm>
<HAS_SPEC, Stainless Steel Kitchen Rack, Load 8kg per tier>
<HIGHLIGHTS, Stainless Steel Kitchen Rack, Foldable>
<HIGHLIGHTS, Stainless Steel Kitchen Rack, Anti-rust>
<COMPLIES_WITH, Stainless Steel Kitchen Rack, Lead-Free>
<COMPLIES_WITH, Stainless Steel Kitchen Rack, Food Contact Safe>注入到 System Prompt:
text
你是有 10 年经验的亚马逊高级运营。请基于以下知识图谱三元组撰写 Listing。
【知识图谱事实】
<MADE_OF, ...>
<HAS_SPEC, ...>
...
【硬约束】
1. 严禁生成与三元组冲突的描述
2. 严禁使用违禁词(FDA approved, antibacterial, #1, ...)
3. Bullet 顺序:场景 → 参数 → 卖点 → 售后 → 品牌大模型推理
调用 GPT-5.5 / Gemini 3 Pro 生成最终内容,模型在硬约束下输出。
关键工程优化
优化 1:实体去重与合并
text
首次抽取:"304 stainless"
二次抽取:"304 SUS Stainless Steel"
三次抽取:"Grade 304 Stainless"
通过向量相似度(cosine > 0.92)自动合并为同一实体节点。优化 2:权重学习
kg_relations.weight 字段决定召回顺序:
text
初始权重 = 1.0
随着用户反馈:
- 用户保留生成结果 → 涉及的关系 weight × 1.05
- 用户重新生成 → 涉及的关系 weight × 0.95
- 经过 N 次迭代后,关键卖点的 weight 会 > 不重要规格
排序时按 weight DESC,最重要的 3-5 条进入 Bullet。优化 3:跨 SKU 知识沉淀
同一类目的多个 SKU 共享 UseCase / Compliance 节点:
text
SKU_A (厨房收纳架_1) ──SUITABLE_FOR──→ Small_Kitchen_Apartment
↑
SKU_B (厨房收纳架_2) ──SUITABLE_FOR────────┤
│
SKU_C (厨房收纳架_3) ──SUITABLE_FOR────────┘
→ Small_Kitchen_Apartment 的描述文本由所有 SKU 反馈共同优化
→ 后续新 SKU 直接复用这个高质量场景描述性能数据
| 阶段 | 耗时 | 说明 |
|---|---|---|
| 实体抽取 | ≈ 6s | Gemini 3 Pro 单次调用 |
| 向量化 | < 200ms | 20 个实体并行 |
| 持久化 | < 50ms | SQLite 单事务 |
| 构图总耗时 | ≈ 6.5s | 实测平均值 |
| 子图召回 | < 60ms | 1 万节点规模 |
| 模板填充 | < 10ms | 字符串拼接 |
| LLM 生成(带约束) | 8-14s | 取决于任务 |
完整调用示例
javascript
// 前端调用
async function generateAllInOne(productInput) {
// 1. 后端抽取实体并构建图谱
const { graphrag_id, entities, relations } = await api.post(
'/api/graphrag/extract',
{ product: productInput }
)
// 2. 前端实时可视化(边构建边显示)
visualizeKnowledgeGraph(entities, relations)
// 3. 并行调用各生成任务
const [mainImage, bullets, aplus, grid4, video] = await Promise.all([
api.post('/api/generate/image', {
task: 'main_image',
graphrag_id // 后端按 task 召回不同子图
}),
api.post('/api/generate/copy', {
task: 'amazon_bullets',
graphrag_id
}),
api.post('/api/generate/image', {
task: 'aplus_infographic',
graphrag_id
}),
api.post('/api/generate/image', {
task: 'lifestyle_4grid',
graphrag_id
}),
api.post('/api/generate/video', {
task: 'product_showcase',
graphrag_id
})
])
return { mainImage, bullets, aplus, grid4, video, graphrag: { entities, relations } }
}技术亮点回顾
核心创新
- 实体—关系最小检索单元 —— 比文档片段细 100 倍,召回更精准
- 任务感知子图召回 —— 不同生成任务用不同关系子集
- 三元组硬约束生成 —— "必须 entailed by",从源头消除幻觉
- 关系权重学习 —— 通过用户反馈持续优化
- 复用 SQLite 不引入新依赖 —— 关系表 + 向量 BLOB 混合存储