存储设计
设计目标
复用 SQLite 不引入额外依赖 —— 用关系表 + 向量索引 BLOB 在单文件 SQLite 中实现完整的 GraphRAG 存储。
为什么不用 Neo4j / Pinecone?
| 选型 | 优势 | 劣势 | 决策 |
|---|---|---|---|
| Neo4j | 原生图数据库,Cypher 查询强大 | 部署复杂、JVM 占用大 | ❌ |
| Pinecone / Weaviate | 专业向量库 | 云服务,违背单机部署目标 | ❌ |
| PostgreSQL + pgvector | 强大的关系 + 向量 | 部署需 Postgres | ❌ |
| DuckDB + 向量 | 列存储快 | 缺少向量索引 | ❌ |
| ✅ SQLite + BLOB | 单文件、零依赖、Go 原生支持 | 向量检索需 Go 层算余弦 | ✅ |
为什么 SQLite 够用?
- 1 万节点规模 SQLite 全表扫描余弦计算 < 60ms(Go 层)
- 跨 SKU 实体合并是离线任务,不需要毫秒级响应
- 单机部署是项目核心需求
表结构
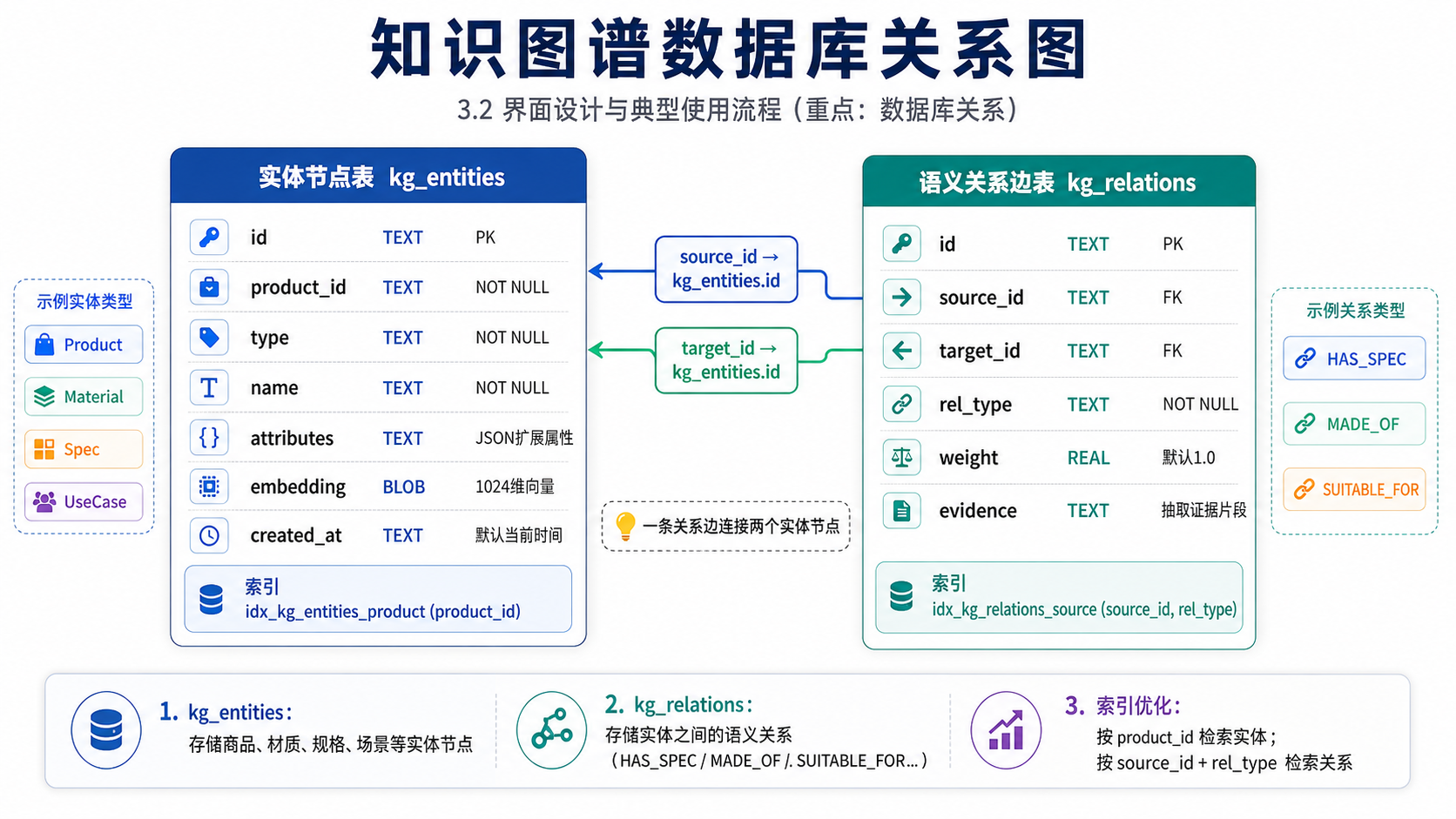
知识图谱核心是两张表 kg_entities 与 kg_relations,前者承载实体节点(含 1024 维向量),后者承载语义关系边。两表通过 source_id / target_id 外键关联。
kg_entities(实体节点)
sql
CREATE TABLE kg_entities (
id TEXT PRIMARY KEY, -- ent_xxx UUID
product_id TEXT NOT NULL, -- 关联商品(图谱根节点)
type TEXT NOT NULL, -- 7 类实体类型
name TEXT NOT NULL,
attributes TEXT, -- JSON 扩展属性
embedding BLOB, -- 1024 维浮点向量(4096 字节)
created_at TEXT NOT NULL DEFAULT (datetime('now'))
);
CREATE INDEX idx_kg_entities_product ON kg_entities(product_id);
CREATE INDEX idx_kg_entities_type ON kg_entities(type);
CREATE INDEX idx_kg_entities_name ON kg_entities(name);kg_relations(语义关系边)
sql
CREATE TABLE kg_relations (
id TEXT PRIMARY KEY,
source_id TEXT NOT NULL,
target_id TEXT NOT NULL,
rel_type TEXT NOT NULL, -- 5 类关系类型
weight REAL NOT NULL DEFAULT 1.0,
evidence TEXT, -- 抽取证据片段
created_at TEXT NOT NULL DEFAULT (datetime('now')),
FOREIGN KEY(source_id) REFERENCES kg_entities(id) ON DELETE CASCADE,
FOREIGN KEY(target_id) REFERENCES kg_entities(id) ON DELETE CASCADE
);
CREATE INDEX idx_kg_rel_source ON kg_relations(source_id, rel_type);
CREATE INDEX idx_kg_rel_target ON kg_relations(target_id, rel_type);
CREATE INDEX idx_kg_rel_weight ON kg_relations(rel_type, weight DESC);向量编码
Embedding 生成
go
func generateEmbedding(text string) ([]float32, error) {
// 调用 Gemini Embedding API
resp, err := geminiClient.Embed(context.Background(), &EmbedRequest{
Model: "text-embedding-004",
Texts: []string{text},
})
if err != nil { return nil, err }
return resp.Embeddings[0], nil // 1024 维 float32
}
// 示例
text := "304 Stainless Steel"
embedding, _ := generateEmbedding(text)
// embedding = [0.0234, -0.0156, 0.0789, ..., 0.0421] 共 1024 个Float32 ↔ BLOB 转换
go
// Go float32 → SQLite BLOB
func encodeEmbedding(emb []float32) []byte {
buf := make([]byte, len(emb) * 4)
for i, v := range emb {
binary.LittleEndian.PutUint32(buf[i*4:], math.Float32bits(v))
}
return buf
}
// SQLite BLOB → Go []float32
func decodeEmbedding(buf []byte) []float32 {
emb := make([]float32, len(buf) / 4)
for i := range emb {
emb[i] = math.Float32frombits(binary.LittleEndian.Uint32(buf[i*4:]))
}
return emb
}
// 写入 SQLite
db.Exec(`
INSERT INTO kg_entities(id, product_id, type, name, embedding)
VALUES (?, ?, ?, ?, ?)
`, id, productID, entityType, name, encodeEmbedding(embedding))容量估算
text
单个实体 BLOB 大小:
1024 维 × 4 字节(float32)= 4,096 字节 ≈ 4 KB
1 万实体的 BLOB 总量:
10,000 × 4 KB = 40 MB
加上索引、关系表,单 SQLite 文件 < 100 MB余弦相似度计算
Go 实现
go
func cosineSimilarity(a, b []float32) float32 {
if len(a) != len(b) { return 0 }
var dot, normA, normB float32
for i := range a {
dot += a[i] * b[i]
normA += a[i] * a[i]
normB += b[i] * b[i]
}
if normA == 0 || normB == 0 { return 0 }
return dot / (sqrt32(normA) * sqrt32(normB))
}SIMD 优化(可选)
go
// 使用 gonum/blas 的 SIMD 优化
import "gonum.org/v1/gonum/blas/blas32"
func cosineSIMD(a, b []float32) float32 {
aVec := blas32.Vector{N: len(a), Inc: 1, Data: a}
bVec := blas32.Vector{N: len(b), Inc: 1, Data: b}
dot := blas32.Dot(aVec, bVec)
normA := blas32.Nrm2(aVec)
normB := blas32.Nrm2(bVec)
return dot / (normA * normB)
}实测性能
- 普通实现:1 万对比较 ≈ 80ms
- SIMD 实现:1 万对比较 ≈ 20ms
当前 1 万节点规模无需 SIMD,未来扩展可启用。
实体相似查询
应用场景
text
1. 实体去重:相似实体合并为同一节点
2. 跨 SKU 实体复用:同义场景共用一个 UseCase 节点
3. 模糊查询:用户输入"不锈钢"召回 304 / 316 / 哑光不锈钢查询实现
go
func findSimilarEntities(query string, threshold float32, topK int) ([]Entity, error) {
// 1. 查询向量化
queryEmb, _ := generateEmbedding(query)
// 2. 全表扫描(< 1 万实体规模够用)
rows, _ := db.Query(`
SELECT id, type, name, attributes, embedding
FROM kg_entities
`)
type scored struct {
Entity Entity
Score float32
}
var results []scored
for rows.Next() {
var ent Entity
var embBlob []byte
rows.Scan(&ent.ID, &ent.Type, &ent.Name, &ent.Attributes, &embBlob)
emb := decodeEmbedding(embBlob)
score := cosineSimilarity(queryEmb, emb)
if score >= threshold {
results = append(results, scored{ent, score})
}
}
// 3. 排序 Top-K
sort.Slice(results, func(i, j int) bool {
return results[i].Score > results[j].Score
})
if len(results) > topK { results = results[:topK] }
out := make([]Entity, len(results))
for i, r := range results { out[i] = r.Entity }
return out, nil
}调用示例
go
// 示例 1:查"不锈钢"相似实体
similar, _ := findSimilarEntities("不锈钢", 0.85, 5)
// 返回:304 Stainless Steel / 316 Stainless / 哑光不锈钢 / ...
// 示例 2:实体去重检查
existing, _ := findSimilarEntities("304 SUS", 0.92, 1)
if len(existing) > 0 {
// 合并到 existing[0].ID,不新建实体
} else {
// 新建实体
}子图查询
任务感知召回
sql
SELECT t.id, t.type, t.name, t.attributes,
r.rel_type, r.weight, r.evidence
FROM kg_relations r
JOIN kg_entities t ON t.id = r.target_id
WHERE r.source_id = :product_id
AND r.rel_type IN ('HAS_SPEC', 'HIGHLIGHTS', 'COMPLIES_WITH')
ORDER BY r.rel_type, r.weight DESC;sql
SELECT t.name, r.weight, r.evidence
FROM kg_relations r
JOIN kg_entities t ON t.id = r.target_id
WHERE r.source_id = :product_id
AND r.rel_type = 'SUITABLE_FOR'
ORDER BY r.weight DESC
LIMIT 4;sql
SELECT GROUP_CONCAT(t.name, '; ') AS compliances
FROM kg_relations r
JOIN kg_entities t ON t.id = r.target_id
WHERE r.source_id = :product_id
AND r.rel_type = 'COMPLIES_WITH';反馈学习更新
go
// 用户反馈触发权重调整
func updateRelationWeight(relID, action string) error {
factor := map[string]float32{
"kept": 1.05,
"modified": 1.00,
"removed": 0.95,
"requested": 1.10,
}[action]
_, err := db.Exec(`
UPDATE kg_relations
SET weight = MIN(weight * ?, 2.0)
WHERE id = ?
`, factor, relID)
return err
}跨 SKU 复用
通过实体相似度合并跨 SKU 的 UseCase / Compliance / Audience:
sql
-- 找出所有 product_id 不同但 name 相似的 UseCase 实体
SELECT e1.id, e1.name, e2.id, e2.name
FROM kg_entities e1, kg_entities e2
WHERE e1.type = 'UseCase'
AND e2.type = 'UseCase'
AND e1.product_id != e2.product_id
AND e1.id < e2.id;
-- 在 Go 层计算余弦相似度,> 0.92 时执行合并:
-- 1. 选择 e1 为主节点
-- 2. UPDATE kg_relations SET target_id = e1.id WHERE target_id = e2.id
-- 3. DELETE FROM kg_entities WHERE id = e2.id性能基准
测试环境:MacBook Pro M3, SQLite WAL 模式
| 操作 | 数据规模 | 耗时 |
|---|---|---|
| 单实体写入 | - | < 5 ms |
| 子图召回(5 类) | 1 万实体 | < 60 ms |
| 实体相似搜索(Top-5) | 1 万实体 | < 80 ms |
| 跨 SKU 合并扫描 | 1 万实体 | < 800 ms(离线任务) |
| 关系权重批量更新 | 100 条 | < 10 ms |
数据规模规划
| 阶段 | 实体数 | 关系数 | SQLite 大小 | 说明 |
|---|---|---|---|---|
| MVP(当前) | < 1,000 | < 2,000 | < 10 MB | 比赛演示 |
| 小规模生产 | < 10,000 | < 30,000 | < 100 MB | 中小卖家 |
| 中规模生产 | < 100,000 | < 500,000 | < 2 GB | 团队产品 |
| 超大规模 | > 100,000 | > 1,000,000 | - | 建议迁移到 Neo4j + pgvector |
备份与迁移
bash
# SQLite 单文件备份(含 GraphRAG 数据)
cp backend/data/app.db backup/app-$(date +%Y%m%d).db
# 导出图谱为 GraphML(可导入 Neo4j)
go run scripts/export_graphml.go > graph.graphml
# 导入 Neo4j(未来扩展)
neo4j-admin import --nodes=kg_entities.csv --relationships=kg_relations.csv